倒排索引
倒排索引(英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。
- 反向索引数据结构是典型的搜索引擎检索算法重要的部分。
- 一个搜索引擎执行的目标就是优化查询的速度:找到某个单词在文档中出现的地方。以前,正向索引开发出来用来存储每个文档的单词的列表,接着掉头来开发了一种反向索引。 正向索引的查询往往满足每个文档有序频繁的全文查询和每个单词在校验文档中的验证这样的查询。
- 实际上,时间、内存、处理器等等资源的限制,技术上正向索引是不能实现的。
- 为了替代正向索引的每个文档的单词列表,能列出每个查询的单词所有所在文档的列表的反向索引数据结构开发了出来。
- 随着反向索引的创建,如今的查询能通过立即的单词标示迅速获取结果(经过随机存储)。随机存储也通常被认为快于顺序存储。
(引自维基百科)
索引构建过程
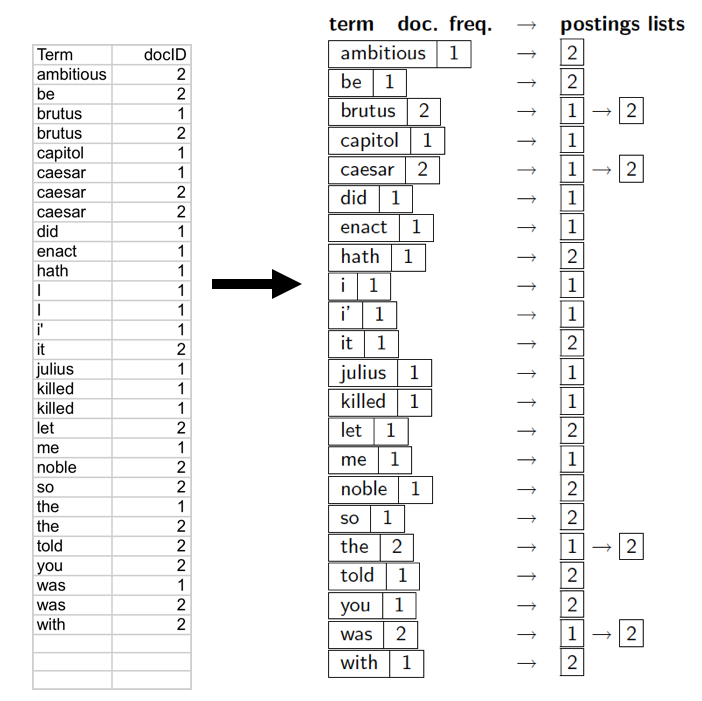
词条序列
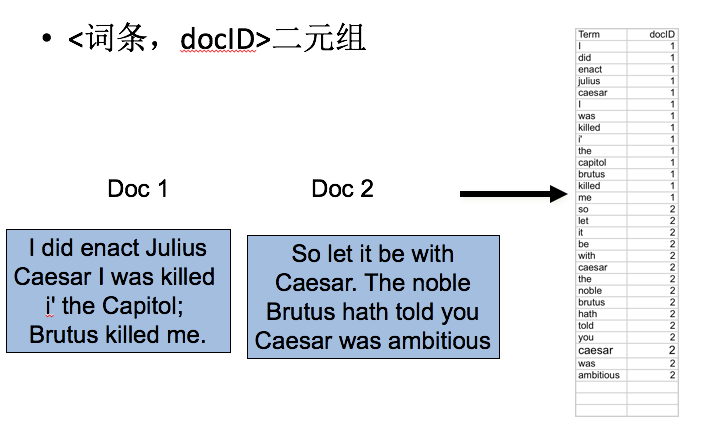
排序

词典&倒排记录表
某个词项在单篇文档中的多次出现会被合并。
拆分成词典和倒排记录表两部分。
每个词项出现的文档数目(doc. frequency, DF)会被加入。
任务
- 子任务1:建索引
- 子任务2:布尔查询
- 文本处理要求
- 不要求做词条变化如friends -> friend等,直接用空格作为分割符。
- 都转成小写。
- 要求
- 输入
- 给定的文档
- 一个布尔查询Q(And Or 操作)
- 支持连续输入查询
- 输出
- 倒排索引表(存成文件dict.index)
- 从文件中读取索引用于查询
- Q的查询结果(界面输出文档名列表)
- 输入
python实现
create_inverse_index.py
创建索引表的文件,事实上在实现时并没有完全按照上面的方法构建索引表,利用python的 set 类可以把步骤合起来。
1 | # -*- coding: utf-8 -*- |
search.py
布尔查询的文件。需要注意的是其中的 search_index 方法,这里因为约定了输入查询的格式所以对于keywords的数量可以明确知道,因此使用下表的方法获得数据。事实上平时使用的检索(如百度)不会限制查询的词数(当然也不能太长了)而且各个词之间都是and布尔操作。
1 | # -*- coding: utf-8 -*- |
测试样例
测试文档可以自己编写。
1 | 请输入查询的内容:rose |